投稿
エヴァンゲリオンは竹取物語である
「エヴァンゲリオンは壮大な近未来 “竹取物語” である. 日本最古のSFを,日本最新のSFとして焼き直したものである」 エヴァ好きの学生がいまして,「結局,あのストーリーで伝えたかったことは何なんでしょうか?」と聞いてきたので,このように答えました. 他に意見を同じくする人はいないものかとググったら,やっぱりおりました.以下のサイトでも紹介されています.同志一名,少し安心しました. http://homepage3.nifty.com/mana/sinwa.htm あれって1995年の作品ですよね.90年以降に生まれた学生はリアルタイムで見ているわけじゃないですよね(私もリアルタイムじゃないけど). 最近になって新劇場版(2007年〜)が制作されていますが,旧作のほうから興味持って見ている大学生もいるようです. さて,エヴァンゲリオンのどこらへんが竹取物語なのか?というところを説明しましょう. まず「竹取物語」のストーリーをささっと紹介しておきます.竹取物語は, ********** 正式には「竹取の翁の物語」という. 月の都で罪を犯した「かぐや姫」.罰として下界への流刑処分となり,刑に服するため竹の中で嬰児となっていた. それを見つけた “竹取りのお爺さん”.女の子を「かぐや姫」と名付けてお婆さんと一緒に大切に育てる. 「かぐや姫」は普通の人間よりも早く成長するようで,たった3ヶ月で成人. 都で噂されるほどの美人であるかぐや姫は,連日多くのプレイボーイから求婚される. 彼らを鬱陶しく思ったかぐや姫.結婚条件として無理難題をふっかけ,彼らを次々と不幸と死に追いやる. ついには時の帝もかぐや姫ゲットに乗り出し天皇パワーで追い詰めるが,「実は私,ヒトじゃないのです」とかぐや姫.“発光体”に姿を変えてみせ,帝の度肝を抜く. いつの日からか,かぐや姫は涙を流すようになる.四六時中泣き続けるかぐや姫.聞けば服役期間が終了するため,月に帰らなければならないとのこと. 「そうはいくか!」とお爺さん.帝の協力を得ることもでき,弓兵の大量投入により自宅を対空防御要塞とする. ついに夜空からやってきた飛ぶ車を伴う天人たち.用意した弓兵は精神攻撃と脱力感に苛まれて動けない.やっとの思いで射た矢も天人や飛ぶ車には当たらな
独学で統計処理作業をスキルアップさせるための本

昨年からボチボチと 「統計」 に関する記事をいろいろと書いてきました. 統計学の原理原則や基礎的な考え方を紹介するのではなく(そんなサイトやブログは山ほどあるから), 「で,結局どういう作業をすればいいの?」 とか, 「統計処理ってSPSSとかExcelの関数や分析ツールに任せてるけど,そもそもどんな計算をしているものなの?」 という極めてマイナー,且つ,どうでもいい興味を持った人の視点で書いてきました. でも,こういう需要は少ないながらもあるようでして,Googleとかで統計処理に関する適当な検索をかけたら私のブログのページが上位に上がってきます. 少し怖いです. Amazon広告 さて, 今回はそんな 「統計学に少しだけ興味があるけど,本格的には勉強したくない」 という人のために,“ほんのり甘い” 味がする統計学の書籍を紹介します. 食前酒用の度数の低い甘いワインみたいな本です. 調子にのってたくさん飲んだら気持ち悪くなるヤツ. アレです. ちゃんと書籍にあたって勉強すればいいものを, 「 Excel 多重比較 」 なんていう検索ワードをGoogleにかけ,私のブログで付け焼刃的な勉強を企む人でも分かりやすい本です. 外部サイトにも有益なリストがあります.こちらも参考にしてください. ■ 大学生が自力で「統計学」の勉強をするための良書10選 ■ 1ヶ月で統計学入門したので「良かった本」と「学んだこと」のまとめ まずは, 【 基礎勉強編 】 ■ Jerry R. Thomas, Jack K. Nelson 著 田中喜代次・西嶋尚彦(訳) 『身体活動科学における研究方法』 統計処理だけでなく,研究方法も掲載されているので身体活動科学・スポーツ科学をやっている人は持ってて損はない. t検定の式や統計学の考え方など,このブログではバッサリ割愛してるけど本当は知っとかなきゃいけない基本的な部分をおさえることができる. ■ 永田靖 著 『統計的方法のしくみ』 内容としては上記の『身体活動科学における研究方法』における統計学の部分の上位版的な存在.舐めてかかると痛い目にあう.腰を据えて読む必要がある,正統で硬派な本. ■ 石村貞夫・石村光資郎 著 『入門はじ
スチューデント化された範囲の表の補間
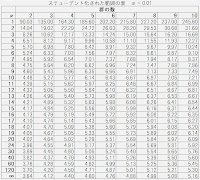
Tukey法とかSteel-Dwass法の計算をするのに,「 スチューデント化された範囲 studentized range 」の表を何度か紹介してきました. 以下の2枚です. 画像の元ファイル(Excel)で確認したい場合は, このリンク先→「 統計記事のエクセルのファイル 」から, 「スチューデント化された範囲の表」 のエクセルファイルをダウンロードしてご確認ください. この表の「ν(自由度)」の数値ですが,例えば上記の表であれば「21」以降の数値は「24」「30」「40」「60」「120」以外の「α」値が分からない,という事になってしまいます. Tukey法を計算したくても,N数が「43」とかだったらα値が分からないわけです. そこで今回は,このスチューデント化された範囲の表に書かれていない自由度(ν)の部分のα値を算出する方法を簡単に示したいと思います. 今回の例としては,上記の有意水準5%の表で, 【3群】で【 自由度(ν):22 】 のところのα値を知りたいということにしておきます. 補間するために必要なのは,知りたい値の自由度に一番近い上下の「自由度」と「α」の値です. 今回の例で言うと,以下のような状況になります. ということで,知りたい【 自由度:22 】のα値ですが,以下のように計算していきます. 一気に1つのセルで計算しきってもいいのですが,整理していきます. まずは計算Aということで,このような式をどっかのセルに入れます. =(1/B3-1/B4)/(1/B2-1/B4)*C2 お次は計算Bとして,こんな感じに. =(1/B2-1/B3)/(1/B2-1/B4)*C4 それぞれエクセルの表中の数値を参照して計算していますので,知りたい値が変われば「スチューデント化された範囲」の表の値に合わせて各々の値も変わります. 最後に,C3のセルに計算Aと計算Bの値を合算しておきます. ということで, 「3.55」が3群で自由度:22の時のα値です. ちょっとした計算ですが,知っているとお得ですね. 参考文献:永田靖・吉田道弘『統計的多重比較法の基礎』 ※後日,こんな怪しいブログよりも信頼性が高いものに触
Steel-Dwass法をExcelで計算する方法について,もう少し詳細に

昨日に引き続き,「スチューデント化された範囲の表」を使った多重比較ということで,Tukey-Kramer法の次はSteel-Dwass法です. 以前のSteel-Dwass法の記事である, ■ ノンパラメトリック版Tukey法による多重比較「Steel-Dwass法」 で紹介した例ですと,以下のような問題点があります. その記事の最後でも触れましたが, (1)各群データの繰り返し数(N数)が一緒でなければいけない (2)同順位のデータ(同じ値)はどのように処理・計算するのか? というものです. この点につき,Tukey法については,昨日の記事で「Tukey-Kramer法」を紹介することで解決しました. 今度はSteel-Dwass法の番です. 以下の記事を読んでも不安がある場合や,元の作業ファイルで確認したい場合は, このリンク先→「 統計記事のエクセルのファイル 」から, 「Steel-Dwass法(異なるN数・同順位データの場合)」 のエクセルファイルをダウンロードしてご確認ください. 細かいところについては,上記に示している以前の記事を読んでもらうとして,今回扱うデータは以下の様なものです. 以前のデータを少し変えています. B列とF列に各群の元データ,C列とG列にそれぞれの組み合わせにおける数値の順位を示しています. そして,D列とH列に,それぞれの組み合わせにおける数値の順位を2乗した値を示しています.この数値とその合計は,あとで出てきますので. ちなみに,上から順に,「A群とB群」「A群とC群」「B群とC群」を比較しています. 以前の記事のデータと違うのは,B群とC群のN数が「6個」になっていることと,B群とC群に同値のデータ「24」が入っていることです. さて, まず一点目,「 データ数が群によって違う場合について 」ですが,見てお分かりのように,気にせず順位を付けていけばOKです. 二点目の「 同順位のデータの処理・計算 」ですが,三段目の「B群とC群」のところに示したように,「24」を両方共「9.5」番目として処理しています. 9番目と10番目に相当するはずだった値ですから(この表現で分かりますか?),その間をとって
繰り返し数(N数)が異なる群を,Excelを使ってTukey法で多重比較する
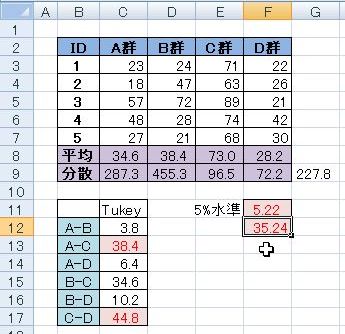
長いタイトルになり,長い月日が経過しましたが,そういうことをしてみたいと思います. いわゆる Tukey-Kramer(テューキー・クレーマー)法 というやつです. 以下の記事を読んでも不安がある場合や,元の作業ファイルで確認したい場合は, このリンク先→「 統計記事のエクセルのファイル 」から, 「繰り返し数が異なる群のTukey法による多重比較」 のエクセルファイルをダウンロードしてご確認ください. 繰り返し数(N数)が同じ群でのTukey法による多重比較は,3ヶ月前に書いた ■ ExcelでTukey法による多重比較 をご覧ください. というか,その続きとして書きますので,以下のエクセルの作業状況を写した画像を見て意味不明な人は,先に上記の記事を読むことを強くオススメします. 上記の画像は, F12の【35.24】という値よりも,C12~17に示した値が大きれば,そこの組み合わせに有意性が認められる,ということを示したものです. 具体的には,A群とC群,C群とD群に有意性が認められています. では,以下のような繰り返し数が異なるデータであれば,どのような計算をするのでしょうか? というのが,今回の内容です. 以前のデータと違い,A群は5群,B群とC群は6群,D群は4群です. 以前紹介したTukey法ですと,全ての計算式を 【N数は5】 ということで統一していますので,今回のようにN数が異なる場合には採用できません. 以前のKramer法で用いる5%水準は,【スチューデント化された範囲の表】における, ※以下,その「表」.クリックしたら大きなサイズで見れます. 群数: 4 ν(データ数): 5 である,「 5.22 」を採用していましたが,今回のTukey-Kramer法では「ν」を, 総データ数 - 群数 の数値で読みとります. 今回の例題ですと, 21 - 4群 = 17 ですので, 群数: 4 ν: 17 である「4.02」を採用します. 以下がそのエクセルの画像です. あと,C13~C18までの各群の組み合わせについては,以前と同様,平均値の引き算をABS関数で絶対値にしています. で,この各群間の「平均値の差」を